trade system
このパッケージは株式データの運用,取引の可視化,ポートフォリオ選択のための方策決定アルゴリズム,価格データの回帰(todo),バックテスト(todo)のためのモジュールからなります. 現在利用できるのは以下の部分です.
- 株式データの取得・利用(
get_stock_price,portfolio/price_supply) - ポートフォリオ選択のための深層強化学習環境(
portfolit/rl_base/envs) - 取引の可視化(
visualization)
株式データの取得・利用
データの取得
データは基本的にpandas.DataFrameとして扱います.
import sys
sys.path.append("./trading_system")
from get_stock_price import YahooFinanceStockLoaderMin
stock_names = ["4755.T",]
stockloader = YahooFinanceStockLoaderMin(stock_names, stop_time_span=2.0, is_use_stop=False, to_tokyo=True)
stock_df = stockloader.load()
stock_df.tail(5)
| Open_4755 | High_4755 | Low_4755 | Close_4755 | Volume_4755 | |
|---|---|---|---|---|---|
| timestamp | |||||
| 2020-11-20 14:55:00+09:00 | 1127.0 | 1128.0 | 1126.0 | 1128.0 | 41000.0 |
| 2020-11-20 14:56:00+09:00 | 1127.0 | 1128.0 | 1126.0 | 1128.0 | 53300.0 |
| 2020-11-20 14:57:00+09:00 | 1128.0 | 1129.0 | 1127.0 | 1128.0 | 20000.0 |
| 2020-11-20 14:58:00+09:00 | 1128.0 | 1130.0 | 1127.0 | 1130.0 | 76000.0 |
| 2020-11-20 14:59:00+09:00 | 1129.0 | 1130.0 | 1128.0 | 1129.0 | 94000.0 |
*2021年11月現在yahoo-finance apiは利用できない状況です
データベースへのupsert
テーブルのカラム数に上限があるため,銘柄コードごとに複数のテーブルに割り振られます.timestampにタイムゾーン情報がある場合でも対応するUTCに変換されます,
from pathlib import Path
from get_stock_price import StockDatabase
db_path = Path("db/test_db") / Path("stock.db")
stock_db = StockDatabase(db_path)
stock_db.upsert(stock_df, item_replace_type="replace_null")
期間を指定してデータを取得
複数の銘柄のデータを結合して返すので,データの存在する期間が異なる場合は注意が必要です.期間をNoneとすることで全てのデータが得られますが,データが膨大になるためおすすめしません.
from pathlib import Path
import datetime
from pytz import timezone
stock_names = ["6502"]
jst_timezone = timezone("Asia/Tokyo")
start_datetime = jst_timezone.localize(datetime.datetime(2020,11,18,9,0,0))
end_datetime = jst_timezone.localize(datetime.datetime(2020,11,18,15,0,0))
query_df = stock_db.search_span(stock_names=stock_names,
start_datetime=start_datetime,
end_datetime=end_datetime,
freq_str="10T",
to_tokyo=True
)
query_df.tail(5)
| Open_6502 | High_6502 | Low_6502 | Close_6502 | Volume_6502 | |
|---|---|---|---|---|---|
| timestamp | |||||
| 2020-11-18 14:10:00+09:00 | 2840.0 | 2845.0 | 2835.0 | 2836.0 | 54900.0 |
| 2020-11-18 14:20:00+09:00 | 2837.0 | 2838.0 | 2817.0 | 2818.0 | 77700.0 |
| 2020-11-18 14:30:00+09:00 | 2818.0 | 2822.0 | 2810.0 | 2822.0 | 80600.0 |
| 2020-11-18 14:40:00+09:00 | 2823.0 | 2826.0 | 2821.0 | 2824.0 | 71500.0 |
| 2020-11-18 14:50:00+09:00 | 2823.0 | 2835.0 | 2823.0 | 2835.0 | 156600.0 |
深層強化学習の環境
報酬や状態はA Deep Reinforcement Learning Framework for the Financial Portfolio Management Problemを参考にしています.
ハイパーパラメータ
jst = timezone("Asia/Tokyo") # timezone
start_datetime = jst.localize(datetime.datetime(2020,11,10,0,0,0)) # 期間の開始時間
end_datetime = jst.localize(datetime.datetime(2020,12,10,0,0,0)) # 期間の終了時間
ticker_number = 19 # 銘柄の数
window = np.arange(-50, 0) # 利用するデータのウィンドウ
episode_length = 500 # エビソードの長さ
freq_str = "5T" # 足のサイズ
状態
方策と価格データからポートフォリオの遷移を計算するportfolio.trade_transformer.PortfolioTransformerか出力する状態は以下のデータクラスとなります
(実際にはメソッドや他のクラスメンバを持ちます).このデータクラスから強化学習で利用する状態を計算します.
@dataclass
class PortfolioState:
names: np.ndarray # 銘柄名
key_currency_index: int # 基軸通貨のインデックス
window: np.ndarray # データのウィンドウ
datetime: datetime.datetime # データの日時
price_array: np.ndarray # [銘柄名, ウィンドウ(時間)]に対応する現在価格
volume_array: np.ndarray # [銘柄名, ウィンドウ(時間)]に対応する取引量
now_price_array: np.ndarray # 銘柄名に対応する現在価格
portfolio_vector: np.ndarray # ポートフォリオベクトル
mean_cost_price_array: np.ndarray # 銘柄名に対応する平均取得価格
all_assets: float # 基軸通貨で換算した全資産
この例では以下のportfolio.rl_base.basis_func.State2Featureを用いて(3, 銘柄名, ウィンドウサイズ)のデータに変換しそれを深層強化学習で利用します.
class State2Feature:
"""
最後に実行
"""
def __call__(self, portfolio_state):
price_array = portfolio_state.price_array
price_portfolio = price_array * portfolio_state.portfolio_vector[:,None]
price_mean_cost = price_array * portfolio_state.mean_cost_price_array[:,None]
feature = np.stack([price_array, price_portfolio, price_mean_cost], axis=0)
return feature
環境
from portfolio.trade_transformer import PortfolioTransformer, PortfolioRestrictorIdentity, FeeCalculatorFree
from portfolio.price_supply import StockDBPriceSupplier
from portfolio.rl_base.envs import TradeEnv, TickerSampler, DatetimeSampler, SamplerManager
sampler
学習に利用する銘柄と期間をサンプリングします.エピソードの開始時にサンプリングし,データベースから対応するデータを取得します.必要があれば初期ポートフォリオベクトルや初期平均取得価格もサンプリングできます.
# sampler
ticker_names_sampler = TickerSampler(all_ticker_names=ticker_codes,
sampling_ticker_number=ticker_number)
start_datetime_sampler = DatetimeSampler(start_datetime=start_datetime,
end_datetime=end_datetime,
episode_length=episode_length,
freq_str=freq_str
)
sampler_manager = SamplerManager(ticker_names_sampler=ticker_names_sampler,
datetime_sampler=start_datetime_sampler,
)
PortfolioTransformer
portfolio.trade_transformer.PortfolioTransformerは前述したように方策とportfolio.price_supply.PriceSuppulierが供給する価格データを元にポートフォリオを遷移させるクラスであり,強化学習だけでなくバックテスト等での利用も想定されています.
# PriceSupplierの設定
price_supplier = StockDBPriceSupplier(stock_db,
[], # 最初は何の銘柄コードも指定しない
episode_length,
freq_str,
interpolate=True
)
# PortfolioTransformerの設定
portfolio_transformer = PortfolioTransformer(price_supplier,
portfolio_restrictor=PortfolioRestrictorIdentity(),
use_ohlc="Close",
initial_all_assets=1e6, # 学習には関係ない
fee_calculator=FeeCalculatorFree()
)
env
trade_env = TradeEnv(portfolio_transformer,
sampler_manager,
window=window,
fee_const=0.0025
)
前処理
ComposeFunctionはtorchvision.transforms.Composeのようにコンストラクタで与えられたcallableなオブジェクトを実行していきますが,辞書を引数にとりアトリビュートとしてcallableなオブジェクトを保持します.
from portfolio.rl_base.basis_func import ComposeFunction, PriceNormalizeConst, MeanCostPriceNormalizeConst, State2Feature
state_transform = ComposeFunction({"price_normalizer":PriceNormalizeConst(None),
"mca_normalizer":MeanCostPriceNormalizeConst(None),
"state2feature":State2Feature()
})
エージェント
この例ではエージェントはPytorchベースの深層強化学習ライブラリであるpfrlのDDPGを用います.方策はポートフォリオベクトルで表されるので,torch.distributionsのディリクレ分布を用いれば確率的方策も扱えます.Pytorchモデルの定義は省略します.
import pfrl
from scipy.special import softmax
policy = DPolicy(in_channels=3, out_number=ticker_number+1)
q_func = QFunc(in_channels=3, action_size=ticker_number+1)
opt_p = torch.optim.Adam(policy.parameters())
opt_q = torch.optim.Adam(q_func.parameters())
rbuf = pfrl.replay_buffers.ReplayBuffer(1.e2)
def action_sample():
portfolio_vector = PortfolioVectorSampler(ticker_number+1).sample()
return portfolio_vector.astype(np.float32)
explorer = pfrl.explorers.ConstantEpsilonGreedy(epsilon=0.3,
random_action_func=action_sample
)
def burnin_action_func():
"""Select random actions until model is updated one or more times."""
random_x = np.random.uniform(np.array([0]*(ticker_number+1)), np.array([1]*(ticker_number+1)))
out = softmax(random_x).astype(np.float32)
return out
#return np.random.uniform(np.array([0]), np.array([1])).astype(np.float32)
if torch.cuda.is_available():
gpu = 0
else:
gpu = -1
phi = lambda x: x.astype(np.float32, copy=False)
ddpg_agent = pfrl.agents.DDPG(
policy,
q_func,
opt_p,
opt_q,
rbuf,
phi=phi,
gamma=0.99,
explorer=explorer,
replay_start_size=100,
target_update_method="soft",
target_update_interval=1,
update_interval=1,
soft_update_tau=5e-3,
n_times_update=1,
gpu=gpu,
minibatch_size=16,
burnin_action_func=burnin_action_func,
)
学習
def episode(env,
agent,
state_transform,
return_state_reward=True,
field_list=["now_price_array", "portfoilo_vector", "mean_cost_price_array", "all_assets", "datetime"],
seed=None,
print_span=None,
is_observe=True):
state_list = []
reward_list = []
portfolio_state,reward,_,_ = env.reset(seed)
#state_transformの設定
state_transform.price_normalizer.const_array = portfolio_state.now_price_array
state_transform.mca_normalizer.const_array = portfolio_state.now_price_array
state_list.append(portfolio_state.partial(*field_list))
reward_list.append(reward)
R = 0
t = 1
obs = state_transform(portfolio_state)
if print_span is not None:
print("initial:, all_assets:{}".format(portfolio_state.all_assets))
while True:
action = agent.act(obs)
portfolio_state, reward, done, info = env.step(action)
state_list.append(portfolio_state.partial(*field_list))
reward_list.append(reward)
R += reward
t += 1
reset = False
# state前処理
obs = state_transform(portfolio_state)
if is_observe: # 観測(学習)する場合
agent.observe(obs, reward, done, reset)
if done:
break
if print_span is not None:
if t%print_span==0:
print("\tt={}:, all_assets:{}".format(t,portfolio_state.all_assets))
if print_span is not None:
print("finished(t={}):, all_assets:{}".format(t, portfolio_state.all_assets))
out_dict = {}
out_dict["R"] = R
if return_state_reward:
out_dict["state_list"] = state_list
out_dict["reward_list"] = reward_list
return out_dict
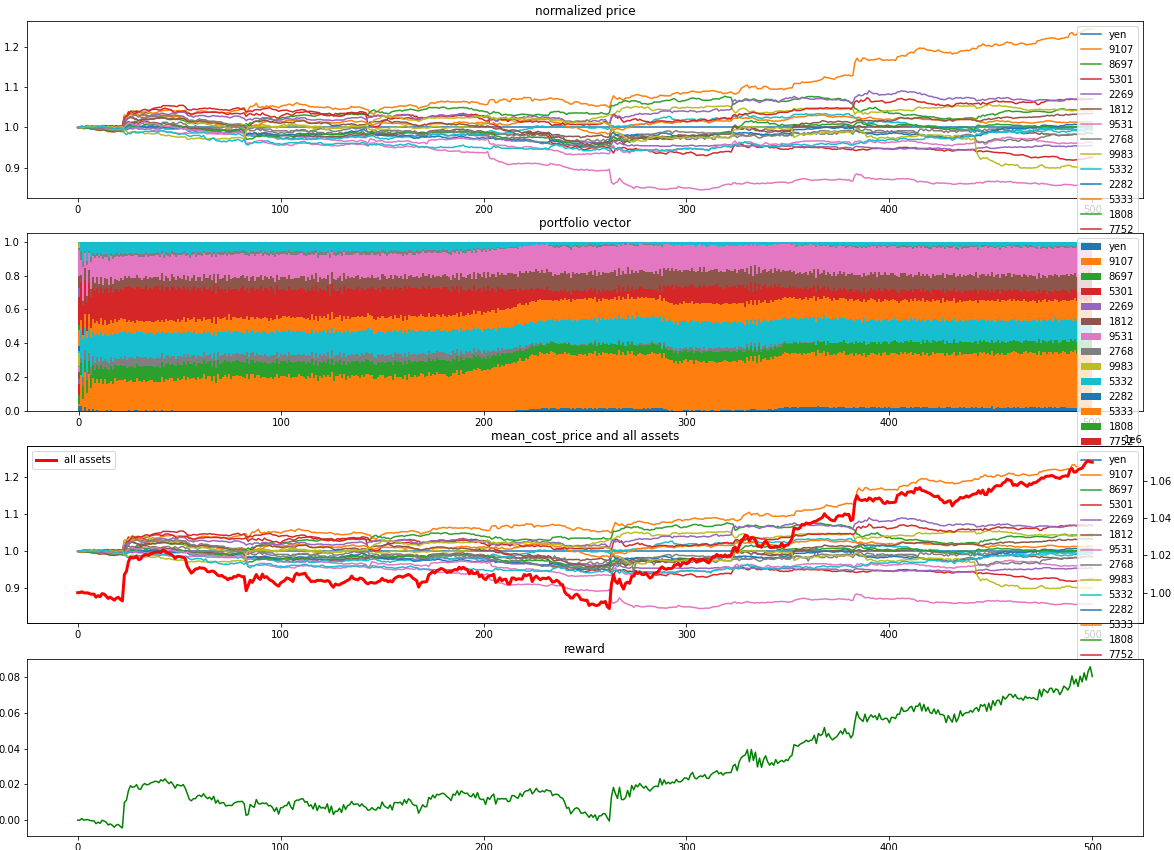
エピソードが100イテレーション毎にvisualization.visualize_portfolio_rl_matplotlibで売買を可視化しています.これはmatplotlibを用いますが,bokehを用いることもできます.
from visualization import visualize_portfolio_rl_matplotlib
for i in tqdm(range(1, n_episodes + 1)):
out_dict = episode(trade_env,
ddpg_agent,
state_transform,
)
if i%50 == 0:
print("episode:{}, return:{}".format(i, out_dict["R"]))
if i%100 == 0:
print("statistics:", ddpg_agent.get_statistics())
if i%100 == 0:
with ddpg_agent.eval_mode():
out_dict = episode(trade_env,
ddpg_agent,
state_transform,
return_state_reward=True,
field_list=["names", "now_price_array", "portfolio_vector", "mean_cost_price_array", "all_assets", "datetime"],
is_observe=False
)
save_fig_path = save_fig_dir_path / Path("trading_process_i_{}.png".format(i))
visualize_portfolio_rl_matplotlib(out_dict["state_list"], out_dict["reward_list"], save_path=save_fig_path, is_show=False, is_save=True, is_jupyter=True)
print("Finshed")